Evaluating LLMs for pharmacovigilance: beyond F1 scores
There is a recurring pattern in papers about LLMs applied to pharmacovigilance. The abstract reports a headline F1 score. The number is high — often above 0.85, sometimes above 0.90. The conclusion is that the model performs well and is promising for drug safety applications.
That framing is not wrong, exactly. But it is dangerously incomplete. And the danger is specific to pharmacovigilance, because the things that matter most in drug safety — rare events, ambiguous cases, negated mentions, edge-case drugs — are precisely the things that aggregate metrics are worst at capturing.
Why F1 is not enough
F1 is a harmonic mean of precision and recall. It is a useful summary when the costs of false positives and false negatives are roughly equal and when the class distribution is roughly balanced. In pharmacovigilance, neither condition holds.
False negatives — missed adverse events — can delay signal detection, omit cases from aggregate analyses, and leave real safety concerns unidentified. False positives — spurious adverse events — can distort disproportionality metrics, waste reviewer time, and generate noise that makes real signals harder to find. The costs are asymmetric, and the direction of asymmetry depends on the use case. For case intake, false negatives may be more dangerous. For signal detection databases, false positives may be more costly.
F1 treats both types of error equally. That alone should make us cautious about using it as the primary evaluation metric in a safety-critical domain.1
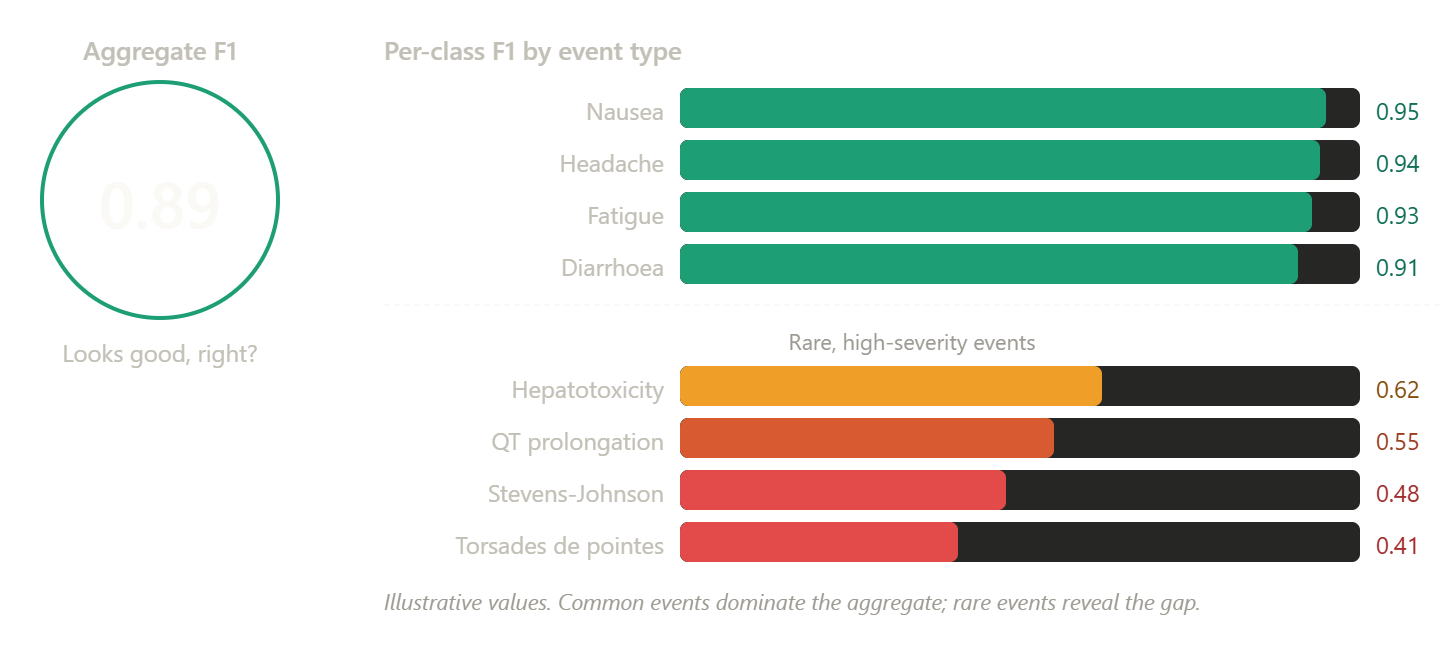
The class imbalance problem
Pharmacovigilance data is deeply imbalanced. A small number of adverse event types account for a large share of reports. Common events like nausea, headache, and fatigue are well-represented in training data and easy for models to detect. Rare but serious events — Stevens-Johnson syndrome, torsades de pointes, progressive multifocal leukoencephalopathy — appear infrequently and are much harder to learn.
A model that correctly identifies common events and fails on rare ones can still achieve a high aggregate F1. The common events dominate the calculation, and the rare events barely move the number. That is the same dynamic that makes aggregate disproportionality metrics unreliable for rare drug-event pairs — the signal drowns in the background.
This is why per-class evaluation is essential. The question is not “how well does this model detect adverse events on average?” The question is “how well does it detect the specific event types where detection failure would have the greatest safety consequence?”
Work on adverse event extraction from drug labels has demonstrated exactly this problem. Performance varies substantially across label sections, text lengths, and linguistic complexity. Negated and discontinuous terms are much harder to extract correctly, and these are precisely the cases where errors have the most downstream impact.1
Calibration: does the model know what it does not know?
A second dimension of evaluation that is almost always missing from pharmacovigilance LLM papers is calibration. Calibration measures whether a model’s stated confidence matches its actual accuracy. A well-calibrated model that says it is 80% confident should be correct about 80% of the time.
Why does this matter? Because in any human-in-the-loop workflow, the model’s confidence score is what determines which cases get routed to human review. If the model is overconfident — consistently reporting high confidence on cases it gets wrong — then reviewers will not see the cases they most need to check. If it is underconfident, the system will route too many cases for review, negating the efficiency gains.
In pharmacovigilance, miscalibration is not a minor inconvenience. It directly affects the reliability of triage systems, the workload distribution for safety reviewers, and the probability that a genuine safety signal makes it through the pipeline.2
Measuring calibration is straightforward. Plot predicted confidence against observed accuracy in binned intervals. Compute the expected calibration error. Report it alongside F1. If a paper does not report calibration, you do not know whether its confidence scores mean anything.
Failure mode taxonomy
A third evaluation gap is the absence of structured failure analysis. Most papers report performance numbers and perhaps an error analysis section with a few examples. What is rarely provided is a systematic taxonomy of failure modes: what types of inputs cause the model to fail, and what types of errors result.
In pharmacovigilance NLP, a useful failure taxonomy might include categories such as negation errors (model extracts a negated event as present), scope errors (model attributes an event to the wrong drug in a multi-drug narrative), coding drift (model produces a plausible but incorrect MedDRA term), hallucinated events (model invents an adverse event not in the source), omission errors (model fails to extract a stated event), and temporality errors (model misinterprets the timing of an event relative to drug exposure).
Each of these failure modes has different downstream consequences and different mitigation strategies. Lumping them all into a single error rate makes it impossible to prioritise improvements or to understand the risk profile of the system.3
The benchmark problem, again
There is a deeper issue here that connects to the reference set problem in signal detection. The benchmark you evaluate against determines the conclusions you draw. If the test set overrepresents common events, clean narratives, and unambiguous cases, the performance numbers will look better than they should. If it underrepresents negation, hedging, multi-drug complexity, and domain-specific jargon, the evaluation will miss the failure modes that matter most.
The SNAX benchmark for adverse drug event detection was designed specifically to address this for negation. It showed that models producing strong results on standard datasets were fragile when exposed to negated and speculated samples, generating a high number of spurious entities. That fragility was invisible in the headline performance numbers.3
The same principle applies more broadly. Any evaluation of an LLM for pharmacovigilance that does not include stress testing against adversarial, ambiguous, and linguistically complex inputs is reporting best-case performance, not expected operational performance.
What better evaluation looks like
Several concrete practices would improve how we evaluate LLMs for drug safety.
First, always report per-class metrics for safety-critical event types, not just aggregate scores. If the model achieves F1 of 0.92 overall but 0.45 on hepatotoxicity-related terms, that is the number the deployment decision should be based on.
Second, report calibration. A model that achieves high F1 but is poorly calibrated is unsuitable for any workflow that relies on confidence-based routing.
Third, construct evaluation datasets that include adversarial and edge-case inputs. Include negated events, speculated events, multi-drug narratives, paediatric cases, consumer-reported narratives, and cases where the adverse event description does not match any standard phrasing.
Fourth, report a structured failure mode analysis. Do not just count errors. Categorise them. A system with 5% extraction errors that are all negation-related has a very different risk profile from one with 5% errors that are randomly distributed.
And fifth, evaluate on data that is representative of the deployment context. A model evaluated on clean clinical trial narratives may perform very differently on consumer-submitted reports, which tend to be more colloquial, less structured, and more linguistically variable.
The uncomfortable truth
Aggregate metrics are popular because they are simple, because they fit in an abstract, and because they make comparison easy. But in pharmacovigilance, ease of comparison is less important than accuracy of risk assessment. A deployment decision based on aggregate F1 alone is a decision made without knowing where the system is most likely to fail.
The uncomfortable truth is that proper evaluation is harder, more expensive, and more time-consuming than reporting a single number. But the consequence of inadequate evaluation in a safety-critical domain is not an embarrassing retraction. It is a missed signal, a miscoded case, or a distorted safety database. Those consequences are real, and they justify the effort.
-
Gisladottir U, Zietz M, Kivelson S, et al. Leveraging large language models in extracting drug safety information from prescription drug labels. Drug Safety. 2025. doi:10.1007/s40264-025-01594-x. ↩ ↩2
-
Hakim JB, Painter JL, Ramcharran D, et al. The need for guardrails with large language models in pharmacovigilance and other medical safety critical settings. Scientific Reports. 2025;15:27886. doi:10.1038/s41598-025-09138-0. ↩
-
Scaboro S, Portelli B, Chersoni E, Serra G, Ferraro G. Increasing adverse drug events extraction robustness on social media: case study on negation and speculation. Journal of Biomedical Informatics. 2023;137:104275. ↩ ↩2